What?
- Purely data-driven method for image relighting.
- Learns to relight scenes by extracting latent representations of scene intrinsics (e.g., albedo) and lighting (extrinsics) from images.
- Link to the paper
Black-box view
- Input: An input image (scene , lighting ) and a reference image (same scene , target lighting )
- Output: A relit image , which approximates but with the lighting from .
Why?
Most state-of-the-art methods (e.g., RGB-X1, IntrinsX2) approach the problem of inverse rendering in an explicit fashion. That is, given some input—usually a photo or a photo with text—they attempt to predict a PBR map consisting of albedo, roughness, metallic properties, and normals. This allows for lighting changes and even editing of material properties, followed by re-rendering the image. However, this approach has two major drawbacks:
- Lack of ground truth data
- Lack of end-to-end learning
First, regarding the lack of ground truth data: while such data does exist (otherwise there would be no deep learning methods for inverse rendering), most of it is not from real-world scenes, as labeling real-world scenes with accurate surface material properties is extremely challenging. Therefore, larger reverse rendering datasets are usually composed of synthetic images rendered from artist-created environments where intrinsic properties are explicitly defined. If the objective is to operate on real-life data, this introduces a domain mismatch problem, as the training data distribution is different from the downstream one, and a model will inevitably have trouble generalising.
Second, the lack of end-to-end learning. When we first predict the intrinsics, we introduce some error in that estimation. Then, when we re-render using a simplified lighting model (since simulating the full complexity of light is computationally infeasible), we introduce another source of error. These errors compound. In contrast, if we could perform relighting in a single pass, we might reduce the cumulative error and achieve better results.
How?
Architecture
The method uses an autoencoder architecture (U-Net) with shared encoder parameters. An encoder network (E) extracts latent intrinsic features and extrinsic features from input images. A decoder network (D) combines these latent representations to generate the relighted image.
Here is an architecture diagram from the paper:
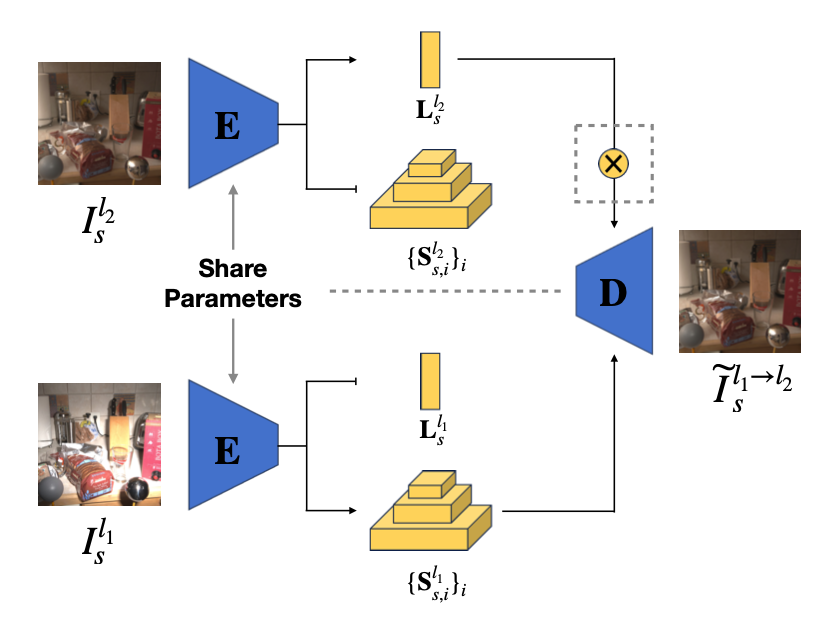
Essentially, the shared encoder extracts scene properties (intrinsics ) and lighting information (extrinsics ) separately from both images. Then the decoder combines the intrinsics extracted from the first image and extrinsics from the second image () to create the new relighted image which should resemble the second image () since the images differ only in lighting conditions so extracted intrinsics should be identical.
Loss Function
The model is trained using a mix of loss functions: relighting loss, intrinsic loss, and extrinsic loss:
Relighting Loss
measures the difference between the generated relit image () and the ground truth (), and also includes a reconstruction term ( vs ). Given our underlying assumption that all pairs of images in our training data differ only by lighting, we want to enforce that the relit image is close to the reference image from which we have taken the extrinsic component, as well as ensure that we can reconstruct the input image from its latent representation. As such, the relight loss is composed of various difference metrics: L2 pixel loss, SSIM (Structural Similarity Index), and L2 gradient loss, which quantify how far apart the decoded images are from their ground truth. All in all, the relighting loss is given by:
Intrinsic Loss
encourages intrinsic codes for the same scene under different lighting conditions ( and ) to be similar. It does so by including an L2 distance between the intrinsics encoded from the images. Furthermore, it includes a regularization term (), based on coding rate, to prevent collapse of the latent representation where all features would be highly correlated. Mathematically, it is given by:
For more details, please refer to the Latent Intrinsics paper. Furthermore, if you would like to better understand why the specific regularization term they utilise works, refer to this paper.
Extrinsic Loss
Promotes diversity and uniform distribution in the extrinsic (lighting) codes , also using the same regularizer as in . It is simply given by:
Footnotes
-
Zeng et al., RGB↔X: Image Decomposition and Synthesis Using Material- and Lighting-aware Diffusion Models, 2024, https://zheng95z.github.io/publications/rgbx24 ↩
-
Kocsis et al.,IntrinsiX: High-Quality PBR Generation using Image Priors, 2025 https://arxiv.org/pdf/2504.01008 ↩